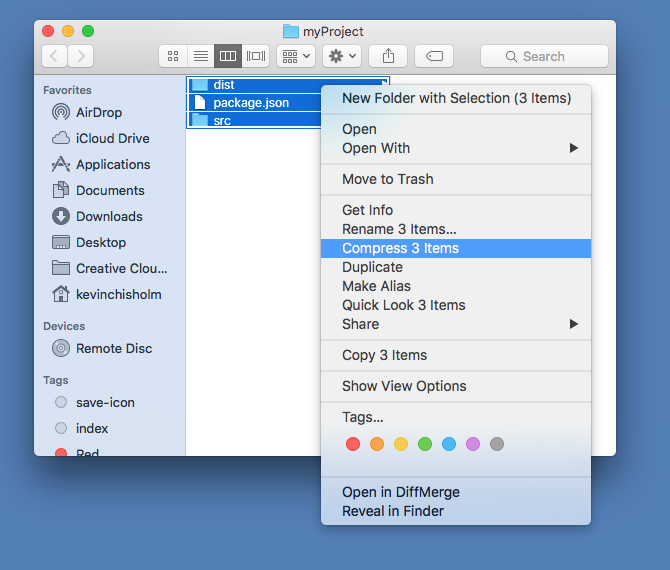
By defining your node module in package.json, you do not need to be concerned about its physical location when referencing it in your code.
By defining your node module in package.json, you do not need to be concerned about its physical location when referencing it in your code.
Sometimes your Node.js application depends on functionality that falls outside of Node’s core components. In this case, you’ll need to import that functionality. This can be achieved with a node module. Organizing your code into modules enforces best-practices such as separation of concerns, code-reuse and test-ability. When you create a custom Node module, you can reference that module’s code in package.json.
So, in this article, I’ll demonstrate how to create a custom Node module for local use. We’ll cover how to reference a local custom Node.js module in package.json, how to expose methods from within that module, and how to access the module from a JavaScript file. To get started, why don’t you go ahead and clone the following github repository: Creating your First Node.js Module
You’ll find instructions on how to run the code in the Git hub page.
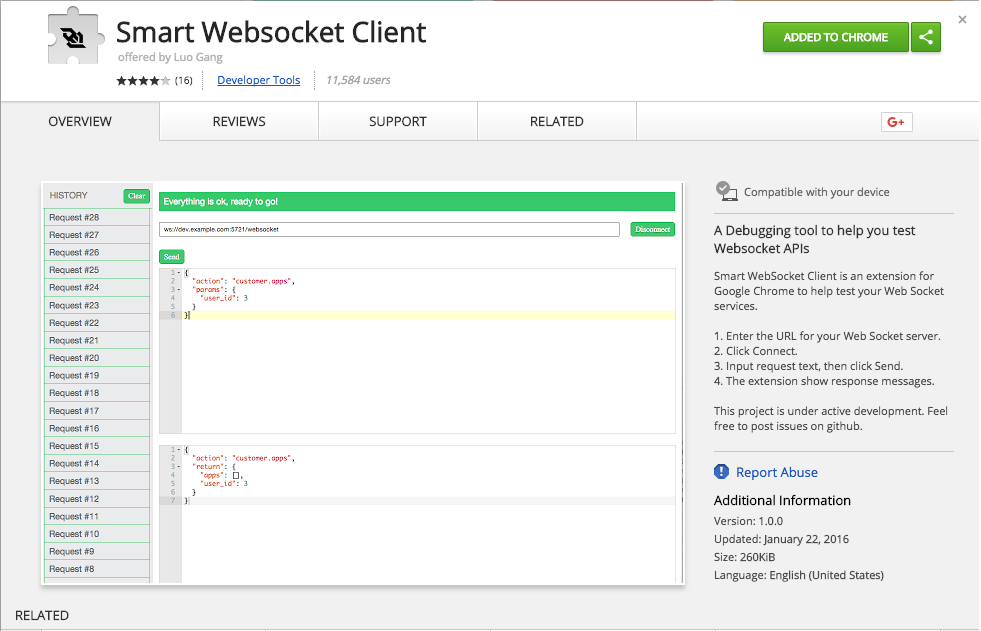
package.json – Example # 1
Example # 1 is the contents of our package.json file. The name and version properties are for demonstration purposes, but the dependencies property is the one that’s important to us. The dependencies property is an object that contains one or more Node modules needed by an application. So, when running the npm install command, node package manager will download all required modules. And the information in the dependencies object will tell node package manager what to download.
Specifying a local file instead of a remote resource
For this project, we use a special syntax to import a module that’s in the local file system. Notice that the value of the dateTools property is: “file:my_modules/dateTools“. This tells node package manager that the dateTools is in the my_modules/dateTools folder.
Our Custom Node Module – Example # 2
In Example # 2, we have the contents of our dateTools module. Now, obviously, this module doesn’t do all that much. It simply shows that there are four methods: getDays, getMonths, getDay, and getMonth, and that there are two arrays: days and months. The idea is that the getDays and getMonths methods return the appropriate arrays, and the getDay, and getMonth methods return the specified day or month, based on the number you pass in as an argument.
So, while this module is not one you would use in a real-world application, it does provide simple methods so that we’ll have some structure to work with.
File Structure
What I really want to focus on for this article is the architecture of the module. So, when you look at the Github repo, you’ll notice that in the dateTools folder, there are two files: index.js and package.json. Now, you may be thinking: “hmmmm… didn’t we already have a package.json file in this application?” Well, yes, we did, but this is the beauty of Node.js: all modules can, in turn, have a package.json file. This way, a module may have its own dependencies, and those dependencies might each have their own dependencies, and so on. So, the idea is that this architecture allows for a highly modular approach to creating software.
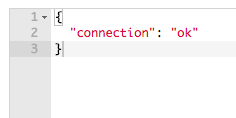
package.json in Our Module – Example # 3
In Example # 3, we have the package.json file that sits in the root of our custom module. The private property indicates that we do not wish to publish this to the npm registry, and the main property indicates the name of the module’s JavaScript file. Our module is the result of this file’s execution.
module.exports
Now, take a look again at Example # 2. On line # 22, you’ll see module.exports = {…}. Every Node module has an object named module.exports, and this object allows the author to make one or more properties and methods available to the outside world. In our case, we provide an object with properties that correspond to four methods. So, this way, when any Node.js code references our dateTools module, it is accessing this module.exports object.
The Demonstration Code – Example # 4
In Example # 4, we have the JavaScript file that demonstrates our module. The most important part of the code is line # 2, where we use the Node.js require method to import our dateTools module. Notice how we reference the module by name: dateTools. This way, we are not concerned with the actual location of the module; the package.json file in the root of our application takes care of that for us. Thus, the name dateTools resolves to the my_modules/dateTools folder, and in that folder, the package.json file resolves the name dateTools to index.js.
Summary
The dateTools module in this article is simple and is designed, primarily, to offer four basic methods as the heart of an introduction to the creation of a custom Node module. The purpose of this custom module was to provide a context for the discussion, and that context was to provide an understanding of your file organization, and how you access your module. The key to much of this discussion was, of course, the file package.json, which allows you to keep your code modular and easy to reference.
I hope that you’ve found this article helpful and that you’re on your way to creating your first custom Node module.