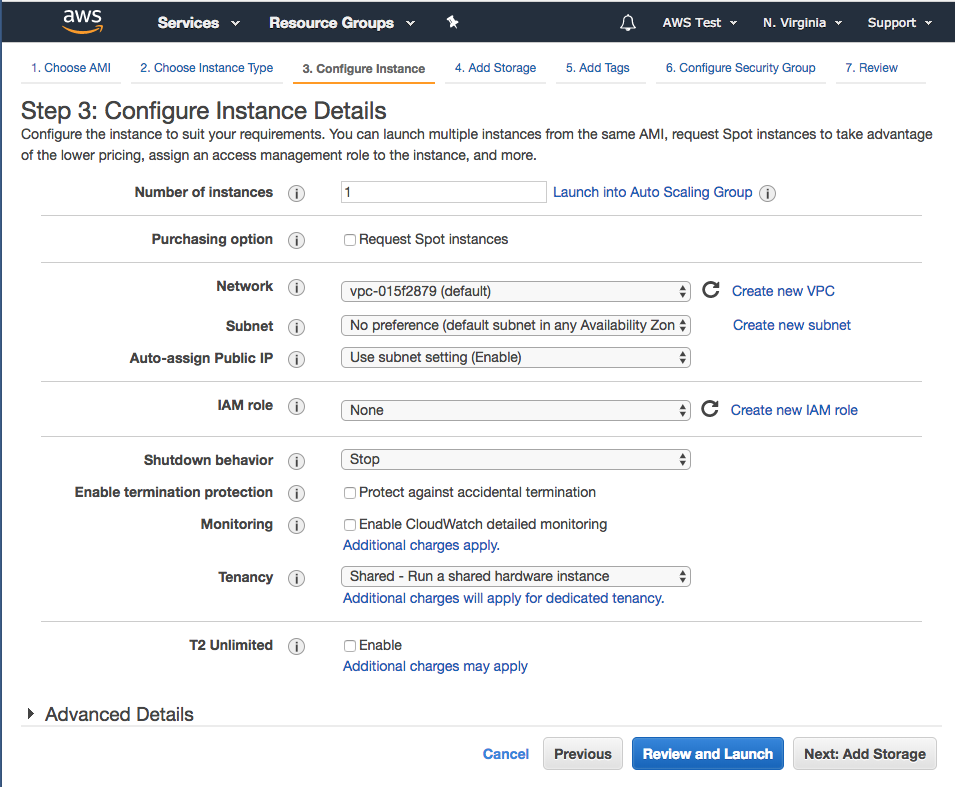
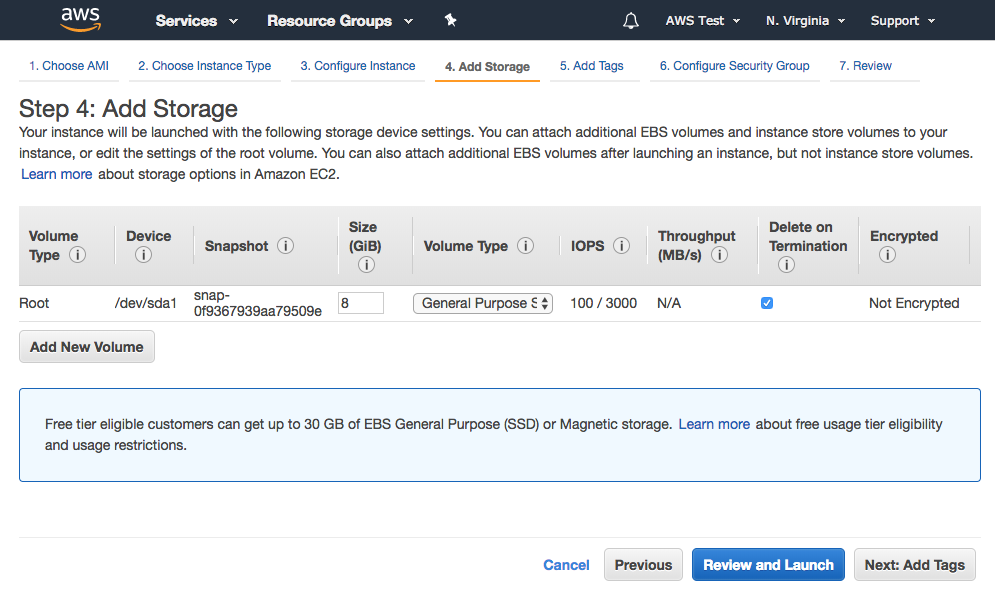
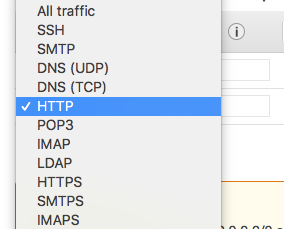
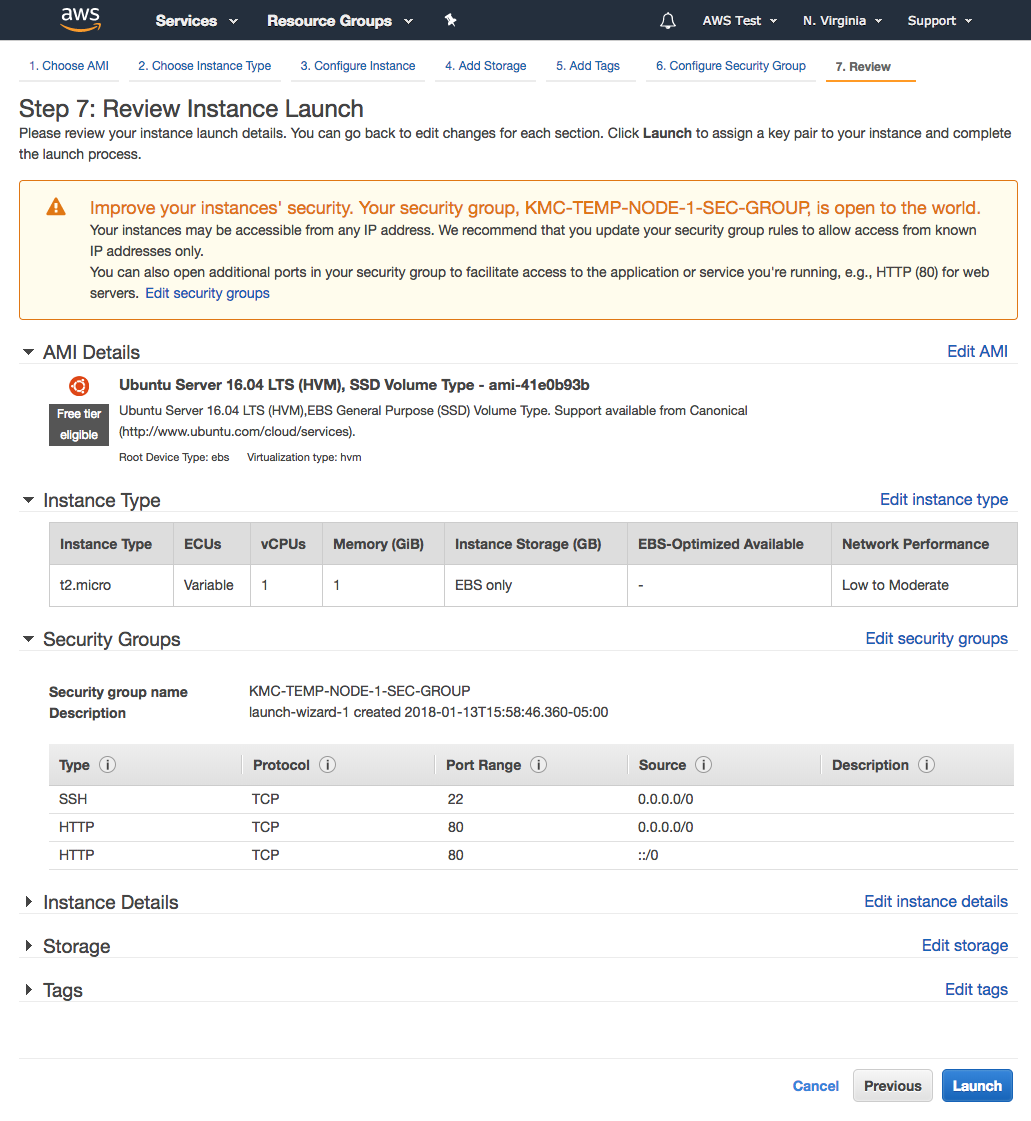
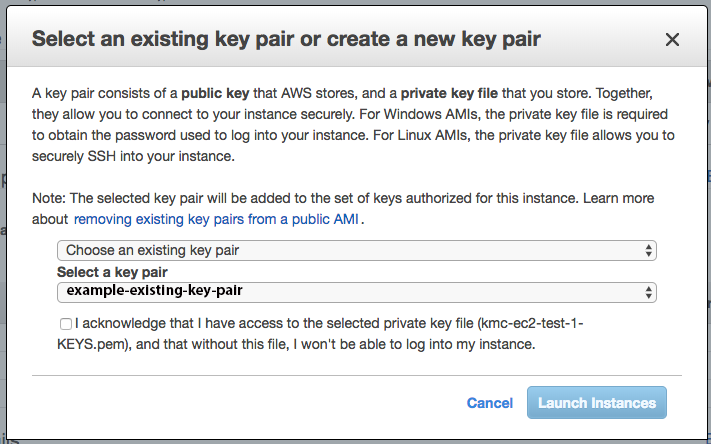
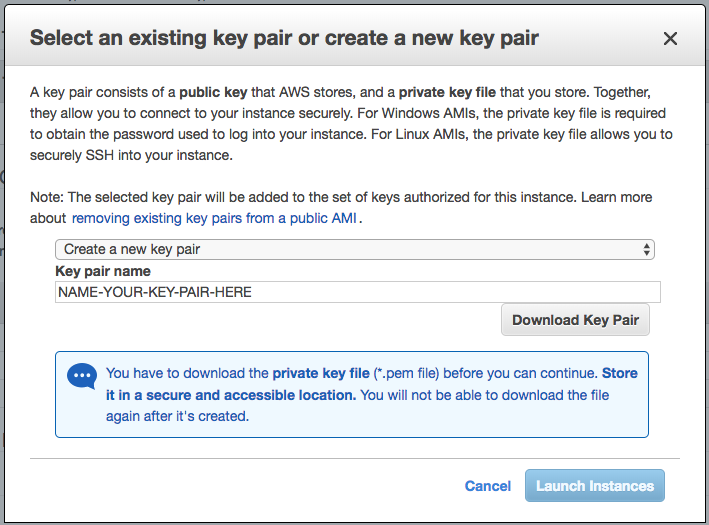
The Rest Parameter allows you to do two things: (1) break out the first X arguments passed-into the function, and (2) put “the rest” of the arguments into an array.
The Rest Parameter allows you to do two things: (1) break out the first X arguments passed-into the function, and (2) put “the rest” of the arguments into an array.
Passing arguments to a JavaScript function is quite common. If a function expects one or more arguments, then it follows that inside of that function you’ll want to examine the incoming arguments. But things can get problematic when you’re not entirely sure exactly what the incoming arguments will be at design time. Now it’s true that inside of any function you have a local variable named “arguments” that is an array-like object, but there are two problems with this array-like “arguments” object.
First of all, it’s not an array, and while you can leverage the Array.prototype object in order to treat the “arguments” object as if it is a true array, that approach feels like a hack. Secondly, if you want to act upon the incoming arguments differently, based on their position, things can get messy. Now this is where the JavaScript Rest Parameter comes in – it’s a powerful tool that can help solve these problems.
Why Should I Care About the JavaScript Rest Parameter?
In this article, I will cover the basics of the JavaScript rest parameter. I’ll walk through the ways in which it can be used to collect the incoming arguments of a function and convert them into a true JavaScript array. I’ll also demonstrate how you can use the JavaScript rest parameter to break out the incoming arguments so that one or more of the initial arguments can be left as is, and then “the rest” of them can be put into an array.
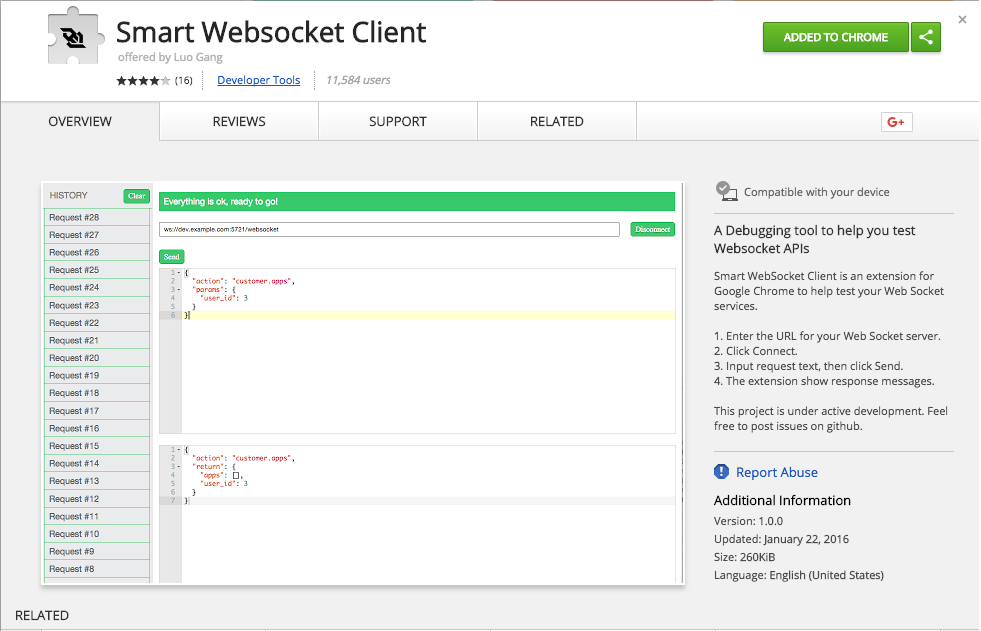
Using the Rest Parameter – Example # 1 A
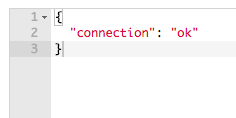
inspectArgs Output – Example # 1 B
Above we’ve created a function named “inspectArgs”, which we’ll use in the rest of the code examples for this article. In Example # 1 A, we use the JavaScript rest parameter to collect all of the arguments that are passed into the function, we and put them into an array. So, on line # 2, since theArgs translates to an array, we can use the forEach method of the “theArgs” variable to iterate that array. Inside of the anonymous callback function that we pass to the forEach method, we have access to each array element, as well as the index of that element. Now using this information, we output the value of each argument, and the index of that argument.
So, the key point here is that by placing “…theArgs” where the incoming arguments would normally go, we are saying: “take all of the arguments that are passed-into this function, put them into an array, and create a local variable for this function named theArgs”. And in Example # 1 B, you can see the output of Example # 1 A, which is exactly what we expect: the value of each argument that was passed to the inspectArgs function.
When you actually want “the rest” of the arguments – Example # 2 A
We See the First Argument, and “the rest” of them- Example # 2 B
Now, in Example # 2A, we made one small change, in order to really demonstrate the power of the JavaScript rest parameter. We changed “…theArgs” to “x, …theArgs” where the incoming arguments would normally go. So, what we are saying to the JavaScript engine here is: “let the first argument be what it is, but then take the rest of the incoming arguments and put them into an array”. So, before we use the “theArgs.forEach” method to iterate the “theArgs” variable, we take a look at the very first argument: “X” and output it.
Now if we take a look at Example # 2 B, we see the output of Example # 2 A. As expected, we see “x -> a” first, because we examined the first argument. Then we see the “rest” of the arguments, because we used the rest parameter to iterate the “rest of” the arguments that were passed into the function.
Skipping Arguments – Example # 3 A
The Second Argument Has Been Skipped – Example # 3 B
In Example # 3 A, we take an approach that’s very similar to that of Example # 2 A, by examining the first argument and outputting it to the console. But when you look at Example # 3 B, the output of this call to inspectArgs skips the second argument: “b”. This is because we specify: “x, y, …theArgs” where the incoming arguments would normally go. So now what we are saying to the JavaScript engine here is: “let the first and second arguments be what they are, but then take the rest of the incoming arguments and put them into an array”. As a result, we wind up with three local variables in this function: “a” “b” and “theArgs”. We output the value of “a” and “theArgs”, but we ignored “b”. The main point here is that we have changed the value of “theArgs” simply by specifying a “b” argument. So, as you can see, Example # 3 A truly demonstrates the power of the JavaScript Rest Parameter.